
How Nokogiri is Used for Scraping Data?

APIs (Application Program Interfaces) are wonderful because they allow huge quantities of data to be exchanged over the web and used by programmers to construct or improve a limitless number of apps. Here, you will use Open Trivia Database which has been used previously. Several APIs like Google Maps API are used by various developers to insert map into their own websites.
Web scraping is exactly scraping the web (or more accurately, the HTML on the web) for the information you require.
When you visit a website, such as www.nytimes.com, we have access to the HTML that directs to that website. Navigate to the page in question, then go to the View menu, pick Developer from the drop-down menu, and then click Inspect Elements (if you're on a Mac). When you do so, a handy box will display on the side or at the bottom of your website. Below shown image is the demo for the same.

The HTML in the toolbox is the same HTML being displayed in the browser window by your browser. In this blog, we'll make use of the Developer Tool Box. Locate the small box with the arrow pointing to it in the navigation pane of your Developer Tool Box when your Elements tab is active. Click on that...
You'll notice that particular components of the website will now be highlighted if you move your mouse over them. When you click on that highlighted part again, the text is no longer highlighted, but a section of the HTML in the Elements window is
This HTML code corresponds to the highlighted element in the text. When it comes to scraping the web, this element-selection tool is a must-have.
The Target
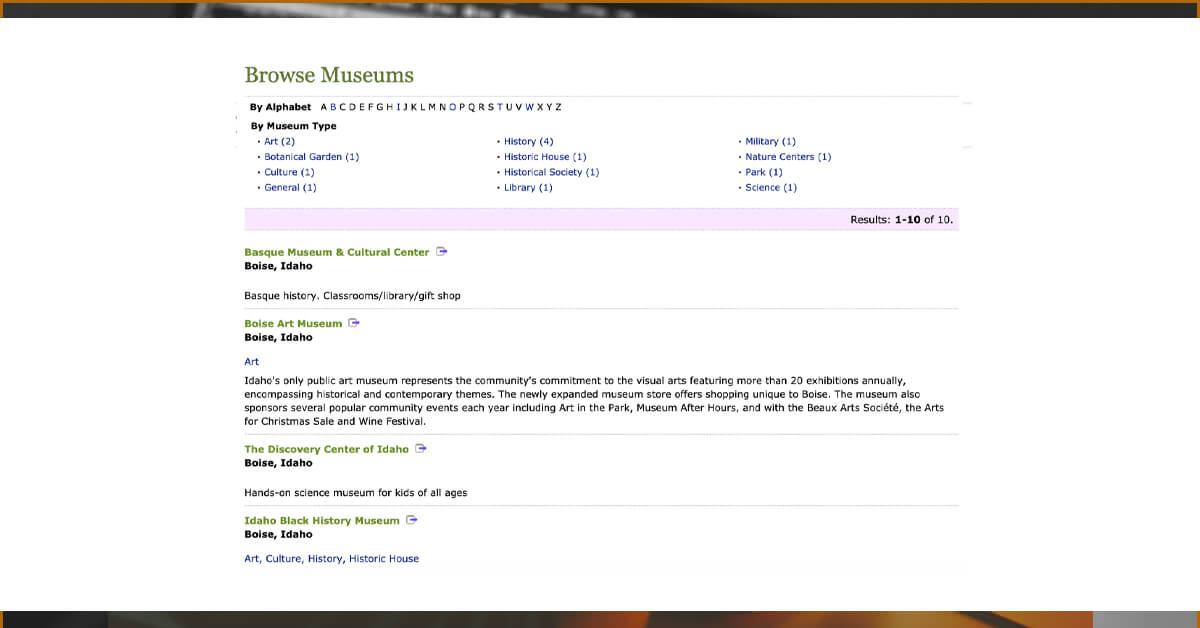
The main goal is to create a web application that allows people to view information about all of Idaho's museums. It would be really helpful to have a database that stores this information in order to accomplish this. Museumsusa.org is a fantastic site with a big database of museum information that can be searched by state.

Whenever you click on a city, you will be redirected to website with data of all 10 museums in Boise, Idaho, which includes the museum’s name, city and state, categories to which it belongs and its brief description.
Setting up the Script
Let's start by creating a new API Rails app from the command line
rails new idaho_museums --api
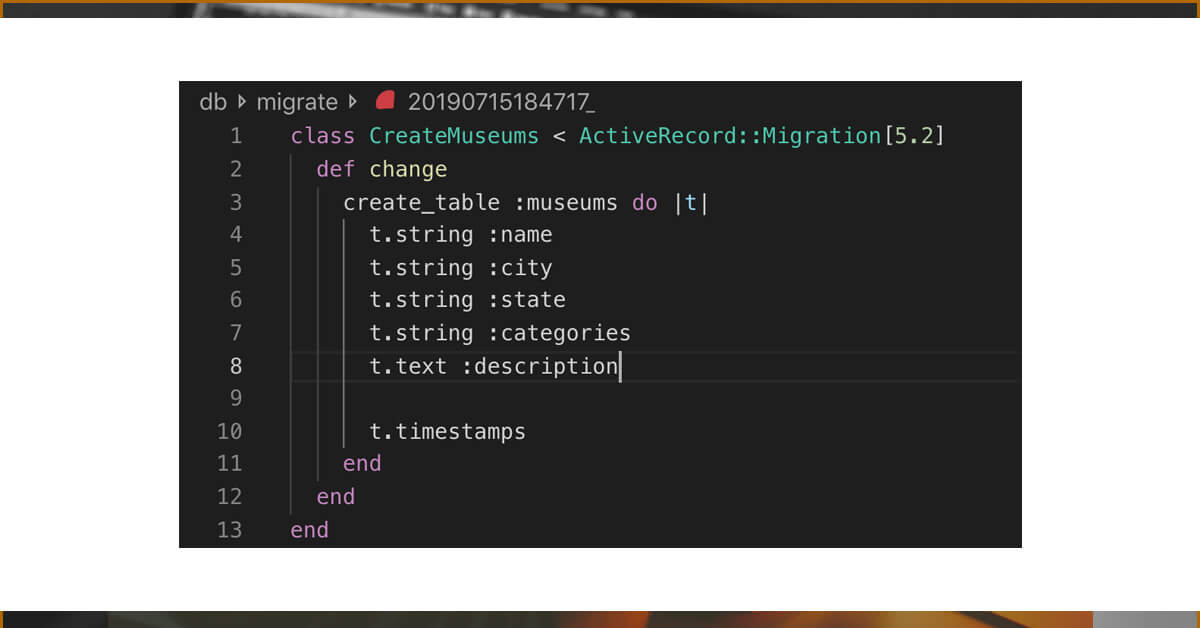
Setting up a model for your museums is the first thing you will need to do.
rails g model Museum
This produces two files: a museum file in app/models and a migration.rb file in db/migrate. Let's get started filling up the museums table's columns with the information we know we can get on the museumsusa.org website. Our migration will look like this once everything is filled out
Before we start scraping, we need to add the nokogiri gem to our Gemfile and run bundle install to install it.

bundle install
Developing the Scraper
We'll need to do a few things with our Scraper model: first, we'll need to collect all of the URLs for each city from our main Idaho museums page; then, using those URLs, you will navigate to each city's page; and finally, from each city's page, you will need to create an instance of museum using information scraped from the HTML of that page. This appears to be quite a task, so let's take it one step at a time.
Create a scraper.rb file in app/models. You will need both nokogiri and open-uri at the start of our file because you will be using them. You will not need to install open-uri because it's included in the standard Ruby library and isn't a separate package.

Your base_url (the one that lists all of the cities in Idaho) is found at ‘http://www.museumsusa.org/museums/?k=1271400%2cState%3aID%3bDirectoryID%3a200454'.
You can utilize the open method of open-uri, which takes one parameter, a URL, and returns the HTML content of that URL to us. Next, we'll utilise the Nokogiri::HTML function to retrieve the HTML we just constructed as a collection of nested nodes that we can inspect. This function also accepts one parameter, which is the HTML returned by the open method.
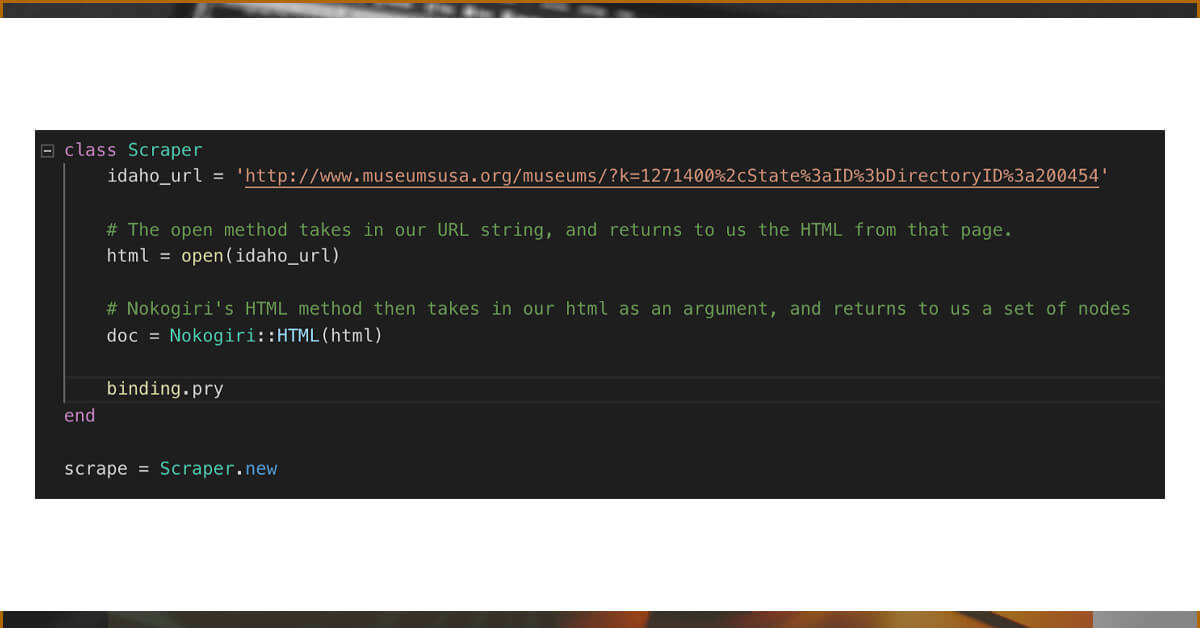
By dropping a binding and establishing a new Scraper instance at the bottom of our file. We can run if we building.pry into our class.
ruby app/models/scraper.rb
You can verify the value of our doc variable from here.
Unlocking the Nokogiri Potential
Nokogiri allows us to scrape our pages using CSS selectors. To do so, we'll use the #css method on the doc variable and supply the CSS selector we wish to target as an argument. Let's have a look at our website once again.
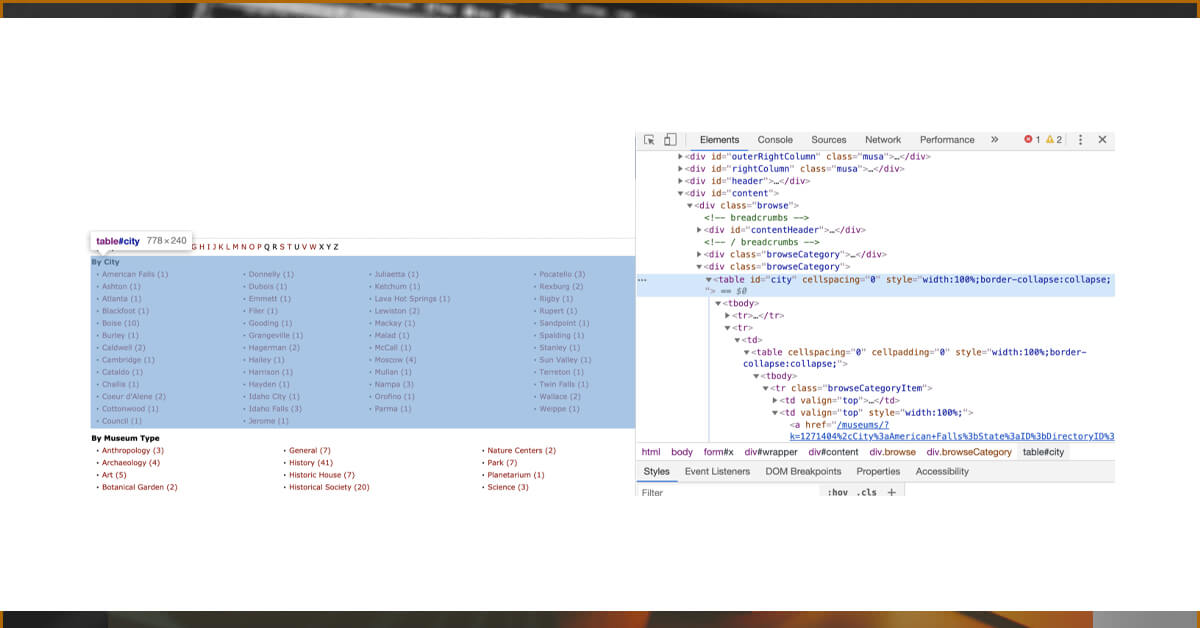
Here you will see three separates <div>s with browseCategory as their class name. The main point of interest here is one in the center with the table of city names. Inspecting that element, you will notice the table contains the id 'city' – this appears to be a good place to start.
Now you will modify my scraper.rb code a little bit, layering everything I've already done into a method called scrape_city_URLs

Here you will use #CSS method
doc.css('#city')
If you are known with CSS selectors, then you will come to know that . denotes a class, # denotes an id, a plain text word (like image) denotes a tag, if you're familiar with CSS selectors.
doc.css('.city')
You will see that the cities are shown as rows in a table when you hover over the targets (the links to each city's website that has that city's list of museums). browseCategoryItem is the class name for each row.

You can connect the #css methods in this way...
doc.css('#city').css('.browseCategoryItem')
So here Nokogiri will check inside the <div> with the id 'city' and gather all of the nested nodes with the class 'browseCategoryItem'.

You will now need to call freshly built method on the scraper instance that will have setup at the bottom of the page. Then verify the worth of towns by dropping inside pry...

This is a big array, and there are anchor tags (a>s) with HREF (Hyperlink references) pointing to URLs. Now, we will add other CSS selectors to query since those anchor tags.
cities = doc.css('#city').css('.browseCategoryItem').css('a')
Check the importance of the cities right here. To initiate, simply fetch the first item in the array.
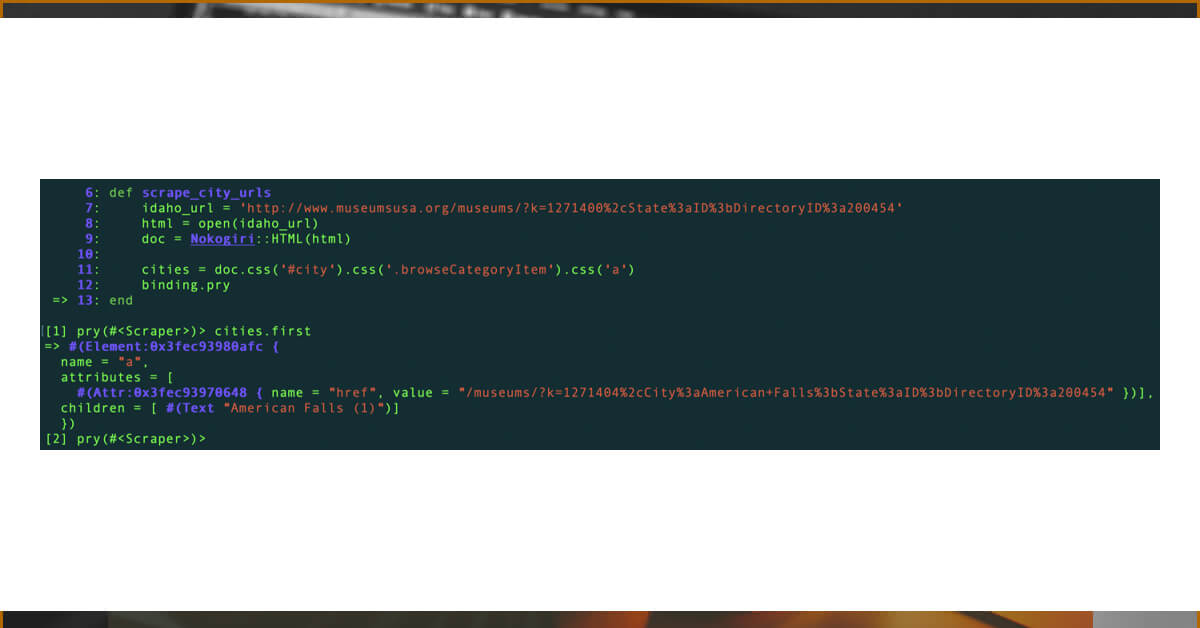
Through our array, we now have access to each <a> tag for each city. Because cities is an array, we can use the #each function to traverse over it.
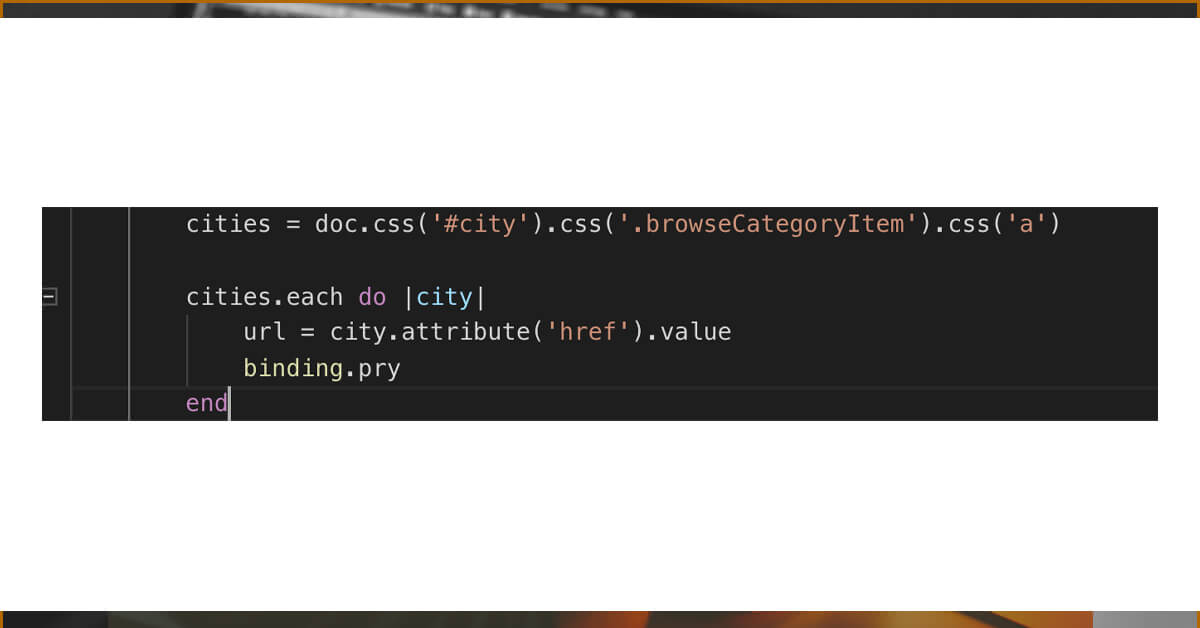
Because every instance of city is an HTML node that refers to an <a> tag, we can now use Nokogiri's #attribute function to capture an attribute of an HTML node by name ('href') and then retrieve its value using the #value method.
Now that we've dropped into pry, you can see that our URL variable returns the URL!

Next step will be those URLs into an array called city URLs, and then check the value of that array by writing it to the console.

We will make a new function that will take care of the following phase. Rather of passing our city_URLs array out at the conclusion of scrape_city _URLs method, we will feed it into my new scrape city pages function.

How will you analyze the HTML within your URLs now that you have access to them inside of this function? Do you recall open-#open URI’s method?
/museums/?k=1271404%2cCity%3aJerome%3bState%3aID%3bDirectoryID%3a200454

Returning to our pry, we can see that the value of doc is now a new list of nodes to investigate.
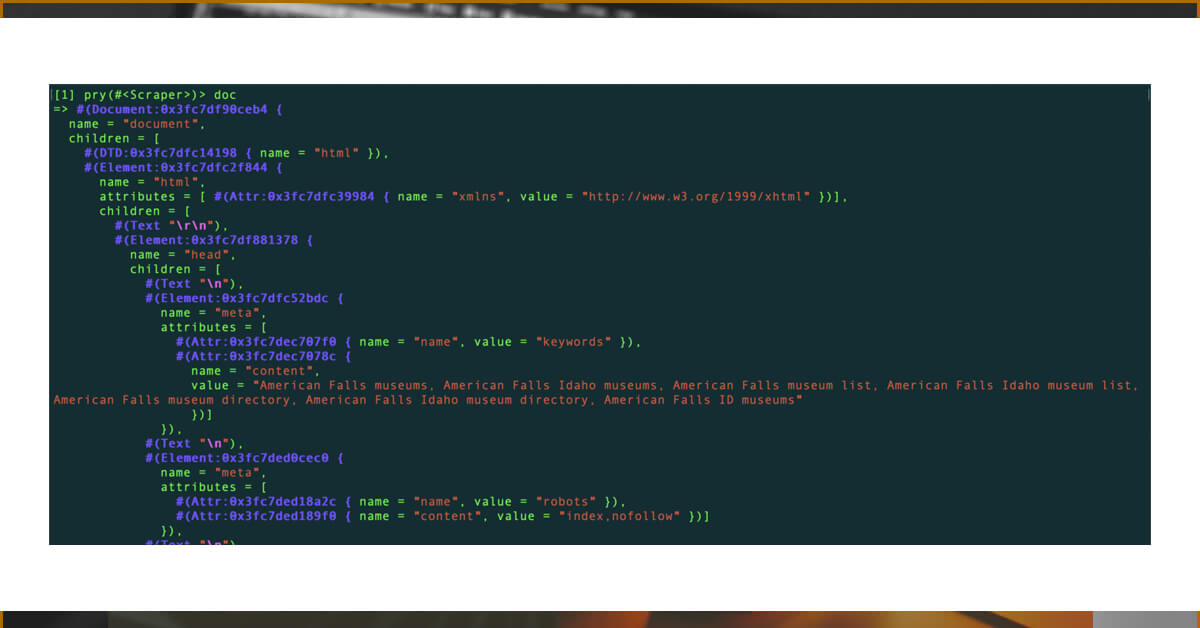
Looking at the properties, we can determine that the HTML is particular to museums in American Falls, Idaho, which is the first city mentioned in Idaho.

Only one museum is displayed in American Falls, and it is presented in a div with the class 'itemGroup'.

A <div> with the class 'itemGroup' is also present on the Boise page. This <div> has two child <div>s with the class names 'item' and 'basic.' When you click on one of those <div>s, you will see the information for: the museum's name, city and state, type, and a brief description. To convert this to code, we'll need...
doc.css('.itemGroup').css('.item').css('.basic')
You can split the div that included two class names ('item' and 'basic') into two css selections.
Set a variable, museums list, to an empty array, and when we loop through our city urls to get those div>s, put them into that array — the goal is to end up with a collection of div>s that individually store the museum information we require.

You will need to execute the scraper to drop back down into our pry.

Now we'll make a new function, which we will create museums. This function will be responsible for scraping the information we need from each node in order to create a museum object in our database. It will take an argument, our list of museum nodes, and will be responsible for scraping the information we need from each node to create a museum object in our database.

We can now return to pry and play around with our museum variable.
Returning to our inspector tools, we can see that the name of our museum is included as the inner text of an a> tag, which is nested inside of a span>, which is nested inside of a div> with the'source' class name.

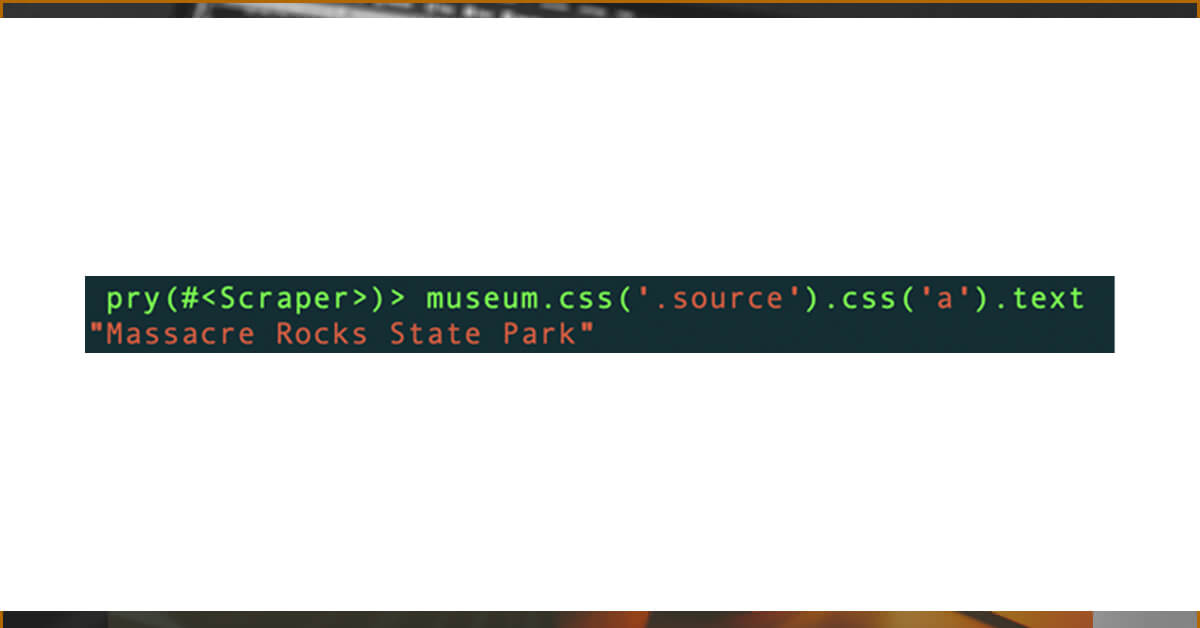
We finally got some clean, useful data after all of that scraping! Now we can go in and add the code to get the name, location, kind, and description of our museum.

Because we want to store both the city and the state separately for location, we can simply divide our location string ("Some City, Some State") on (,), converting our string into an array from which we can get those values individually.
Before moving on to the following step, double-check the values for name, location, type, and desc in your console.
Now we'll generate a museum info hash for each museum, which we'll use to store our museum information to our database later.
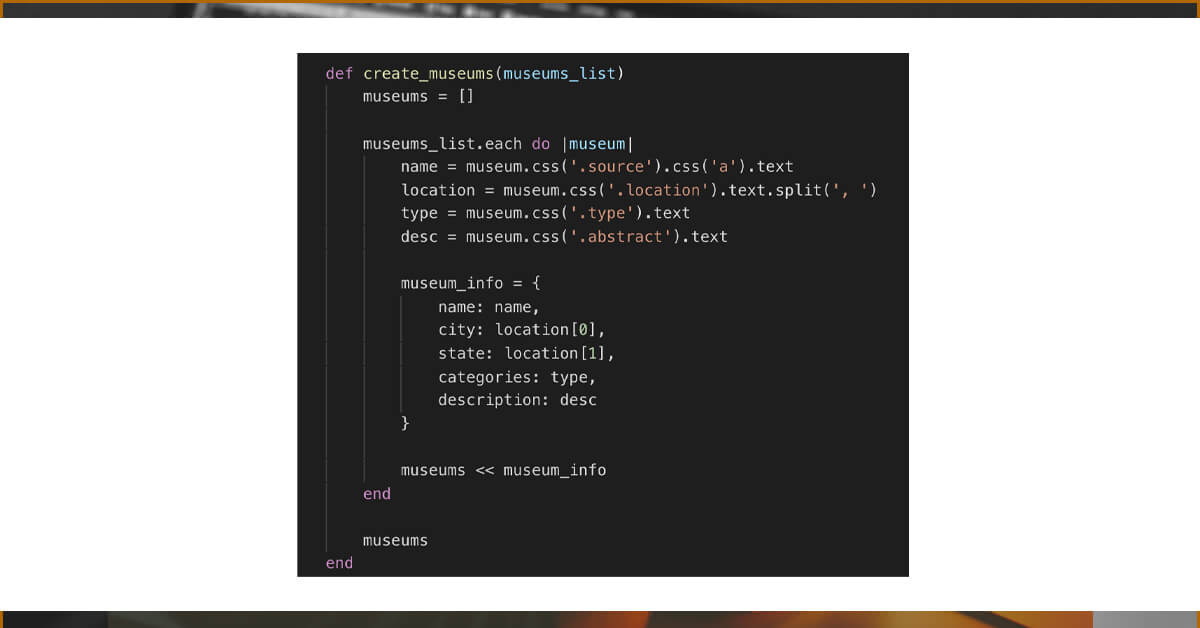
Instead of executing our scraper from within our scraper.rb file, we'll make a few changes so that we can seed our database with the information we scraped.
To begin, we'll enable our museum model to construct instances using the array of museum info hashes we just produced. We'll develop a class function called create museums from collection to accomplish exactly that.
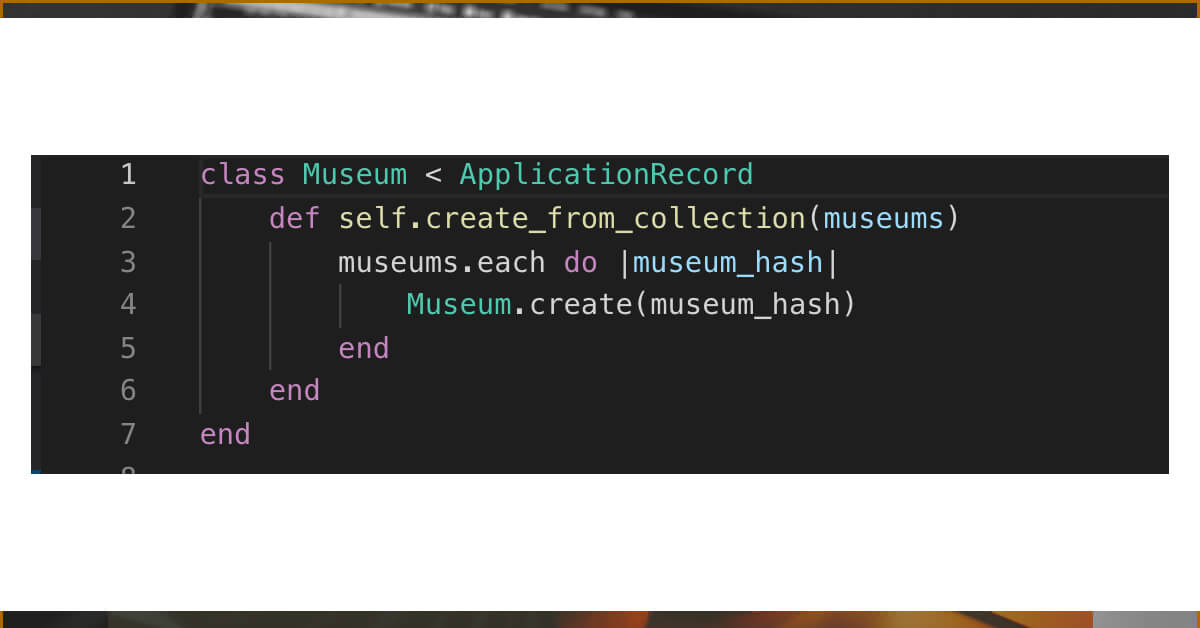
Now we'll go to our db folder, find our seed.rb file, and execute our scraper from there to seed our database.

Returning to our terminal, all we have to do now is execute to seed our database.
rails db:seed

For any web scraping services, contact iWeb Scraping today!!
Reuqest for a quote!!